|
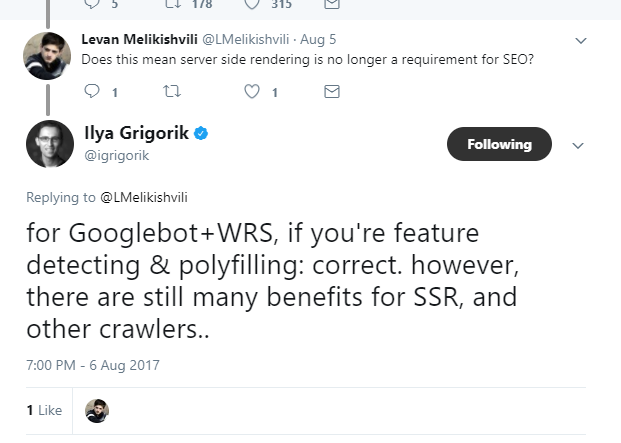
Posted by goralewicz Crawling and indexing has been a hot topic over the last few years. As soon as Google launched Google Panda, people rushed to their server logs and crawling stats and began fixing their index bloat. All those problems didn’t exist in the “SEO = backlinks” era from a few years ago. With this exponential growth of technical SEO, we need to get more and more technical. That being said, we still don’t know how exactly Google crawls our websites. Many SEOs still can’t tell the difference between crawling and indexing. The biggest problem, though, is that when we want to troubleshoot indexing problems, the only tool in our arsenal is Google Search Console and the Fetch and Render tool. Once your website includes more than HTML and CSS, there's a lot of guesswork into how your content will be indexed by Google. This approach is risky, expensive, and can fail multiple times. Even when you discover the pieces of your website that weren’t indexed properly, it's extremely difficult to get to the bottom of the problem and find the fragments of code responsible for the indexing problems. Fortunately, this is about to change. Recently, Ilya Grigorik from Google shared one of the most valuable insights into how crawlers work:
Interestingly, this tweet didn’t get nearly as much attention as I would expect. So what does Ilya’s revelation in this tweet mean for SEOs?Knowing that Chrome 41 is the technology behind the Web Rendering Service is a game-changer. Before this announcement, our only solution was to use Fetch and Render in Google Search Console to see our page rendered by the Website Rendering Service (WRS). This means we can troubleshoot technical problems that would otherwise have required experimenting and creating staging environments. Now, all you need to do is download and install Chrome 41 to see how your website loads in the browser. That’s it. You can check the features and capabilities that Chrome 41 supports by visiting Caniuse.com or Chromestatus.com (Googlebot should support similar features). These two websites make a developer’s life much easier. Even though we don’t know exactly which version Ilya had in mind, we can find Chrome’s version used by the WRS by looking at the server logs. It’s Chrome 41.0.2272.118.
It will be updated sometime in the futureChrome 41 was created two years ago (in 2015), so it’s far removed from the current version of the browser. However, as Ilya Grigorik said, an update is coming:
I was lucky enough to get Ilya Grigorik to read this article before it was published, and he provided a ton of valuable feedback on this topic. He mentioned that they are hoping to have the WRS updated by 2018. Fingers crossed! Google uses Chrome 41 for rendering. What does that mean?We now have some interesting information about how Google renders websites. But what does that mean, practically, for site developers and their clients? Does this mean we can now ignore server-side rendering and deploy client-rendered, JavaScript-rich websites? Not so fast. Here is what Ilya Grigorik had to say in response to this question:
We now know WRS' capabilities for rendering JavaScript and how to debug them. However, remember that not all crawlers support Javascript crawling, etc. Also, as of today, JavaScript crawling is only supported by Google and Ask (Ask is most likely powered by Google). Even if you don’t care about social media or search engines other than Google, one more thing to remember is that even with Chrome 41, not all JavaScript frameworks can be indexed by Google (read more about JavaScript frameworks crawling and indexing). This lets us troubleshoot and better diagnose problems. Don’t get your hopes upAll that said, there are a few reasons to keep your excitement at bay. Remember that version 41 of Chrome is over two years old. It may not work very well with modern JavaScript frameworks. To test it yourself, open http://jsseo.expert/polymer/ using Chrome 41, and then open it in any up-to-date browser you are using. The page in Chrome 41 looks like this:
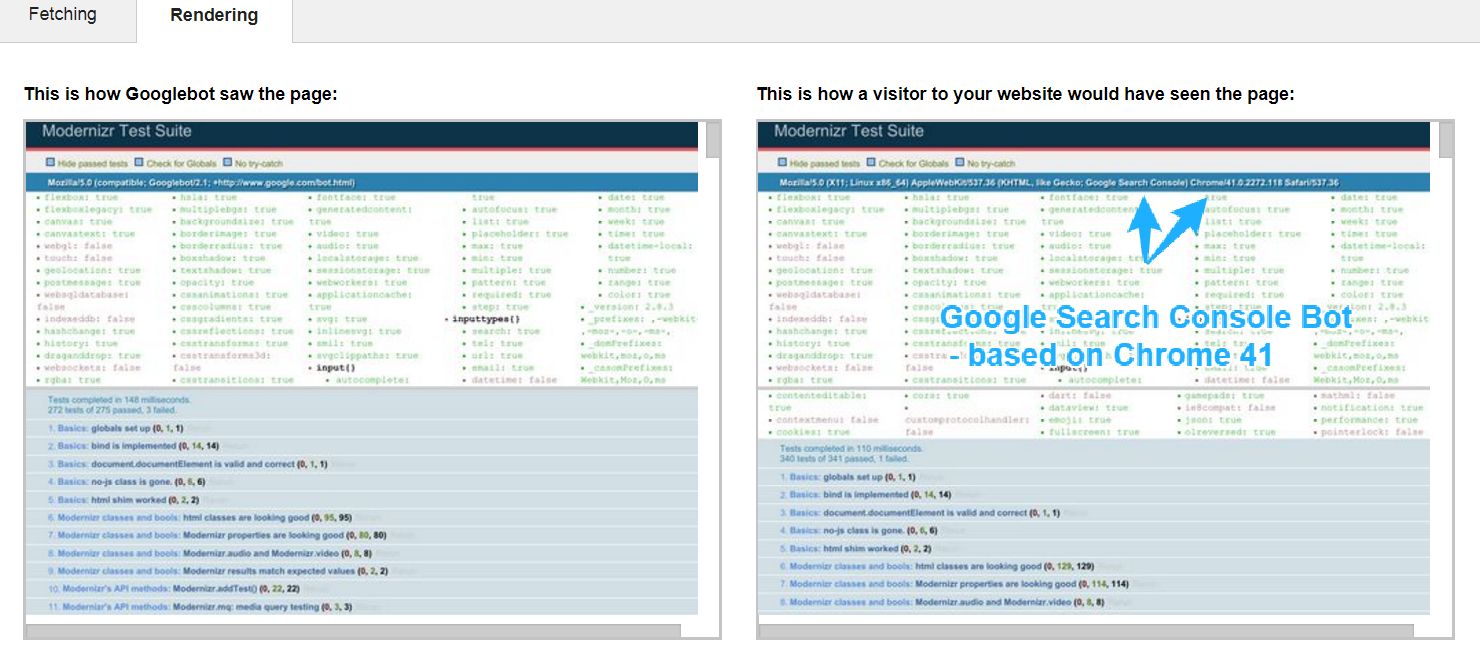
The content parsed by Polymer is invisible (meaning it wasn’t processed correctly). This is also a perfect example for troubleshooting potential indexing issues. The problem you're seeing above can be solved if diagnosed properly. Let me quote Ilya: "If you look at the raised Javascript error under the hood, the test page is throwing an error due to unsupported (in M41) ES6 syntax. You can test this yourself in M41, or use the debug snippet we provided in the blog post to log the error into the DOM to see it." I believe this is another powerful tool for web developers willing to make their JavaScript websites indexable. We will definitely expand our experiment and work with Ilya’s feedback. The Fetch and Render tool is the Chrome v. 41 previewThere's another interesting thing about Chrome 41. Google Search Console's Fetch and Render tool is simply the Chrome 41 preview. The righthand-side view (“This is how a visitor to your website would have seen the page") is generated by the Google Search Console bot, which is... Chrome 41.0.2272.118 (see screenshot below).
There's evidence that both Googlebot and Google Search Console Bot render pages using Chrome 41. Still, we don’t exactly know what the differences between them are. One noticeable difference is that the Google Search Console bot doesn’t respect the robots.txt file. There may be more, but for the time being, we're not able to point them out. Chrome 41 vs Fetch as Google: A word of cautionChrome 41 is a great tool for debugging Googlebot. However, sometimes (not often) there's a situation in which Chrome 41 renders a page properly, but the screenshots from Google Fetch and Render suggest that Google can’t handle the page. It could be caused by CSS animations and transitions, Googlebot timeouts, or the usage of features that Googlebot doesn’t support. Let me show you an example. Chrome 41 preview:
Image blurred for privacy The above page has quite a lot of content and images, but it looks completely different in Google Search Console. Google Search Console preview for the same URL:
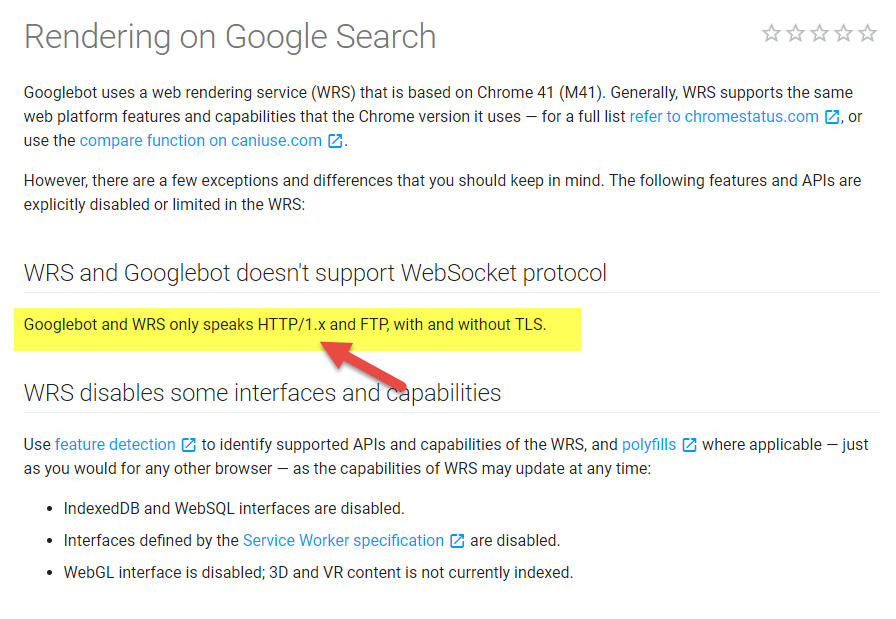
As you can see, Google Search Console’s preview of this URL is completely different than what you saw on the previous screenshot (Chrome 41). All the content is gone and all we can see is the search bar. From what we noticed, Google Search Console renders CSS a little bit different than Chrome 41. This doesn’t happen often, but as with most tools, we need to double check whenever possible. This leads us to a question... What features are supported by Googlebot and WRS?According to the Rendering on Google Search guide:
The last point is really interesting. Despite statements from Google over the last 2 years, Google still only crawls using HTTP/1.1. No HTTP/2 support (still)We've mostly been covering how Googlebot uses Chrome, but there's another recent discovery to keep in mind. There is still no support for HTTP/2 for Googlebot. Since it's now clear that Googlebot doesn’t support HTTP/2, this means that if your website supports HTTP/2, you can’t drop HTTP 1.1 optimization. Googlebot can crawl only using HTTP/1.1. There were several announcements recently regarding Google’s HTTP/2 support. To read more about it, check out my HTTP/2 experiment here on the Moz Blog.
Via https://developers.google.com/search/docs/guides/r... Googlebot’s futureRumor has it that Chrome 59’s headless mode was created for Googlebot, or at least that it was discussed during the design process. It's hard to say if any of this chatter is true, but if it is, it means that to some extent, Googlebot will “see” the website in the same way as regular Internet users. This would definitely make everything simpler for developers who wouldn’t have to worry about Googlebot’s ability to crawl even the most complex websites. Chrome 41 vs. Googlebot’s crawling efficiencyChrome 41 is a powerful tool for debugging JavaScript crawling and indexing. However, it's crucial not to jump on the hype train here and start launching websites that “pass the Chrome 41 test.” Even if Googlebot can “see” our website, there are many other factors that will affect your site’s crawling efficiency. As an example, we already have proof showing that Googlebot can crawl and index JavaScript and many JavaScript frameworks. It doesn’t mean that JavaScript is great for SEO. I gathered significant evidence showing that JavaScript pages aren’t crawled even half as effectively as HTML-based pages. In summaryIlya Grigorik’s tweet sheds more light on how Google crawls pages and, thanks to that, we don’t have to build experiments for every feature we're testing — we can use Chrome 41 for debugging instead. This simple step will definitely save a lot of websites from indexing problems, like when Hulu.com’s JavaScript SEO backfired. It's safe to assume that Chrome 41 will now be a part of every SEO’s toolset. Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger Google Shares Details About the Technology Behind Googlebot
0 Comments
Leave a Reply. |
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
December 2017
Categories |






 RSS Feed
RSS Feed
