|
Posted by sherrybonelli If you're having trouble getting your local business' website to show up in the Google local 3-pack or local search results in general, you're not alone. The first page of Google's search results seems to have gotten smaller over the years – the top and bottom of the page are often filled with ads, the local 7-pack was trimmed to a slim 3-pack, and online directories often take up the rest of page one. There is very little room for small local businesses to rank on the first page of Google. To make matters worse, Google has a local "filter" that can strike a business, causing their listing to drop out of local search results for seemingly no reason – often, literally, overnight. Google's local filter has been around for a while, but it became more noticeable after the Possum algorithm update, which began filtering out even more businesses from local search results. If you think about it, this filter is not much different than websites ranking organically in search results: In an ideal world, the best sites win the top spots. However, the Google filter can have a significantly negative impact on local businesses that often rely on showing up in local search results to get customers to their doors. What causes a business to get filtered?Just like the multitude of factors that go into ranking high organically, there are a variety of factors that go into ranking in the local 3-pack and the Local Finder.
Here are a few situations that might cause you to get filtered and what you can do if that happens. Proximity mattersWith mobile search becoming more and more popular, Google takes into consideration where the mobile searcher is physically located when they're performing a search. This means that local search results can also depend on where the business is physically located when the search is being done. A few years ago, if your business wasn't located in the large city in your area, you were at a significant disadvantage. It was difficult to rank when someone searched for "business category + large city" – simply because your business wasn't physically located in the "large city." Things have changed slightly in your favor – which is great for all the businesses who have a physical address in the suburbs. According to Ben Fisher, Co-Founder of SteadyDemand.com and a Google Top Contributor, "Proximity and Google My Business data play an important role in the Possum filter. Before the Hawk Update, this was exaggerated and now the radius has been greatly reduced." This means there's hope for you to show up in the local search results – even if your business isn't located in a big city. Google My Business categoriesWhen you're selecting a Google My Business category for your listing, select the most specific category that's appropriate for your business. However, if you see a competitor is outranking you, find out what category they are using and select the same category for your business (but only if it makes sense.) Then look at all the other things they are doing online to increase their organic ranking and emulate and outdo them. If your category selections don't work, it's possible you've selected too many categories. Too many categories can confuse Google to the point where it's not sure what your company's specialty is. Try deleting some of the less-specific categories and see if that helps you show up.
Your physical addressIf you can help it, don't have the same physical address as your competitors. Yes, this means if you're located in an office building (or worse, a "virtual office" or a UPS Store address) and competing companies are also in your building, your listing may not show up in local search results. When it comes to sharing an address with a competitor, Ben Fisher recommends, "Ensure that you do not have the same primary category as your competitor if you are in the same building. Their listing may have more trust by Google and you would have a higher chance of being filtered." Also, many people think that simply adding a suite number to your address will differentiate your address enough from a competitor at the same location — it won't. This is one of the biggest myths in local SEO. According to Fisher, "Google doesn't factor in suite numbers." Additionally, if competing businesses are located physically close to you, that, too, can impact whether you show up in local search results. So if you have a competitor a block or two down from your company, that can lead to one of you being filtered. PractitionersIf you're a doctor, attorney, accountant or are in some other industry with multiple professionals working in the same office location, Google may filter out some of your practitioners' listings. Why? Google doesn't want one business dominating the first page of Google local search results. This means that all of the practitioners in your company are essentially competing with one another. To offset this, each practitioner's Google My Business listing should have a different category (if possible) and should be directed to different URLs (either a page about the practitioner or a page about the specialty – they should not all point to the site's home page). For instance, at a medical practice, one doctor could select the family practice category and another the pediatrician category. Ideally you would want to change those doctors' landing pages to reflect those categories, too: Doctorsoffice.com/dr-mathew-family-practice Another thing you can do to differentiate the practitioners and help curtail being filtered is to have unique local phone numbers for each of them. Evaluate what your competitors are doing rightIf your listing is getting filtered out, look at the businesses that are being displayed and see what they're doing right on Google Maps, Google+, Google My Business, on-site, off-site, and in any other areas you can think of. If possible, do an SEO site audit on their site to see what they're doing right that perhaps you should do to overtake them in the rankings. When you're evaluating your competition, make sure you focus on the signals that help sites rank organically. Do they have a better Google+ description? Is their GMB listing completely filled out but yours is missing some information? Do they have more 5-star reviews? Do they have more backlinks? What is their business category? Start doing what they're doing – only better. In general Google wants to show the best businesses first. Compete toe-to-toe with the competitors that are ranking higher than you with the goal of eventually taking over their highly-coveted spot. Other factors that can help you show up in local search resultsAs mentioned earlier, Google considers a variety of data points when it determines which local listings to display in search results and which ones to filter out. Here are a few other signals to pay attention to when optimizing for local search results: ReviewsIf everything else is equal, do you have more 5-star reviews than your competition? If so, you will probably show up in the local search results instead of your competitors. Google is one of the few review sites that encourages businesses to proactively ask customers to leave reviews. Take that as a clue to ask customers to give you great reviews not only on your Google My Business listing but also on third-party review sites like Facebook, Yelp, and others.
PostsAre you interacting with your visitors by offering something special to those who see your business listing? Engaging with your potential customers by creating a Post lets Google know that you are paying attention and giving its users a special deal. Having more "transactions and interactions" with your potential customers is a good metric and can help you show up in local search results.
Google+Despite what the critics say, Google+ is not dead. Whenever you make a Facebook or Twitter post, go ahead and post to Google+, too. Write semantic posts that are relevant to your business and relevant to your potential customers. Try to write Google+ posts that are approximately 300 words in length and be sure to keyword optimize the first 100 words of each post. You can often see some minor increases in rankings due to well-optimized Google+ posts, properly optimized Collections, and an engaged audience. Here's one important thing to keep in mind: Google+ is not the place to post content just to try and rank higher in local search. (That's called spam and that is a no-no.) Ensure that any post you make to Google+ is valuable to your end-users. Keep your Google My Business listing currentAdding photos, updating your business hours for holidays, utilizing the Q&A or booking features, etc. can help you show off in rankings. However, don't add content just to try and rank higher. (Your Google My Business listing is not the place for spammy content.) Make sure the content you add to your GMB listing is both timely and high-quality content. By updating/adding content, Google knows that your information is likely accurate and that your business is engaged. Speaking of which... Be engagedInteracting with your customers online is not only beneficial for customer relations, but it can also be a signal to Google that can positively impact your local search ranking results. David Mihm, founder of Tidings, feels that by 2020, the difference-making local ranking factor will be engagement.
(Source: The Difference-Making Local Ranking Factor of 2020) According to Mihm, "Engagement is simply a much more accurate signal of the quality of local businesses than the traditional ranking factors of links, directory citations, and even reviews." This means you need to start preparing now and begin interacting with potential customers by using GMB's Q&A and booking features, instant messaging, Google+ posts, responding to Google and third-party reviews, ensure your website's phone number is "click-to-call" enabled, etc. Consolidate any duplicate listingsSome business owners go overboard and create multiple Google My Business listings with the thought that more has to be better. This is one instance where having more can actually hurt you. If you discover that for whatever reason your business has more than one GMB listing, it's important that you properly consolidate your listings into one. Other sources linking to your websiteIf verified data sources, like the Better Business Bureau, professional organizations and associations, chambers of commerce, online directories, etc. link to your website, that can have an impact on whether or not you show up on Google's radar. Make sure that your business is listed on as many high-quality and authoritative online directories as possible – and ensure that the information about your business – especially your company's Name, Address and Phone Number (NAP) -- is consistent and accurate. So there you have it! Hopefully you found some ideas on what to do if your listing is being filtered on Google local results. What are some tips that you have for keeping your business "unfiltered"? Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger Unfiltered: How to Show Up in Local Search Results
0 Comments
Posted by randfish One of the most helpful functions of modern-day SEO software is the idea of a "keyword universe," a database of tens of millions of keywords that you can tap into and discover what your site is ranking for. Rankings data like this can be powerful, and having that kind of power at your fingertips can be intimidating. In today's Whiteboard Friday, Rand explains the concept of the "keyword universe" and shares his most useful tips to take advantage of this data in the most popular SEO tools.
Click on the whiteboard image above to open a high-resolution version in a new tab! Video TranscriptionHowdy, Moz fans, and welcome to another edition of Whiteboard Friday. This week we're going to chat about the Keywords by Site feature that exists now in Moz's toolset — we just launched it this week — and SEMrush and Ahrefs, who have had it for a little while, and there are some other tools out there that also do it, so places like KeyCompete and SpyFu and others. In SEO software, there are two types of rankings data:A) Keywords you've specifically chosen to track over timeBasically, the way you can think of this is, in SEO software, there are two kinds of keyword rankings data. There are keywords that you have specifically selected or your marketing manager or your SEO has specifically selected to track over time. So I've said I want to track X, Y and Z. I want to see how they rank in Google's results, maybe in a particular location or a particular country. I want to see the position, and I want to see the change over time. Great, that's your set that you've constructed and built and chosen.
B) A keyword "universe" that gives wide coverage of tens of millions of keywordsBut then there's what's called a keyword universe, an entire universe of keywords that's maintained by a tool provider. So SEMrush has their particular database, their universe of keywords for a bunch of different languages, and Ahrefs has their keyword universe of keywords that each of those two companies have selected. Moz now has its keyword universe, a universe of, I think in our case, about 40 million keywords in English in the US that we track every two weeks, so we'll basically get rankings updates. SEMrush tracks their keywords monthly. I think Ahrefs also does monthly. Depending on the degree of change, you might care or not care about the various updates. Usually, for keywords you've specifically chosen, it's every week. But in these cases, because it's tens of millions or hundreds of millions of keywords, they're usually tracking them weekly or monthly.
So in this universe of keywords, you might only rank for some of them. It's not ones you've specifically selected. It's ones the tool provider has said, "Hey, this is a broad representation of all the keywords that we could find that have some real search volume that people might be interested in who's ranking in Google, and we're going track this giant database." So you might see some of these your site ranks for. In this case, seven of these keywords your site ranks for, four of them your competitors rank for, and two of them both you and your competitors rank for. Remarkable data can be extracted from a "keyword universe"There's a bunch of cool data, very, very cool data that can be extracted from a keyword universe. Most of these tools that I mentioned do this. Number of ranking keywords over time
So they'll show you how many keywords a given site ranks for over time. So you can see, oh, Moz.com is growing its presence in the keyword universe, or it's shrinking. Maybe it's ranking for fewer keywords this month than it was last month, which might be a telltale sign of something going wrong or poorly. Degree of rankings overlap
You can see the degree of overlap between several websites' keyword rankings. So, for example, I can see here that Moz and Search Engine Land overlap here with all these keywords. In fact, in the Keywords by Site tool inside Moz and in SEMrush, you can see what those numbers look like. I think Moz actually visualizes it with a Venn diagram. Here's Distilled.net. They're a smaller website. They have less content. So it's no surprise that they overlap with both. There's some overlap with all three. I could see keywords that all three of them rank for, and I could see ones that only Distilled.net ranks for. Estimated traffic from organic search
You can also grab estimated traffic. So you would be able to extract out — Moz does not offer this, but SEMrush does — you could see, given a keyword list and ranking positions and an estimated volume and estimated click-through rate, you could say we're going to guess, we're going to estimate that this site gets this much traffic from search. You can see lots of folks doing this and showing, "Hey, it looks this site is growing its visits from search and this site is not." SISTRIX does this in Europe really nicely, and they have some great blog posts about it. Most prominent sites for a given set of keywords
You can also extract out the most prominent sites given a set of keywords. So if you say, "Hey, here are a thousand keywords. Tell me who shows up most in this thousand-keyword set around the world of vegetarian recipes." The tool could extract out, "Okay, here's the small segment. Here's the galaxy of vegetarian recipe keywords in our giant keyword universe, and this is the set of sites that are most prominent in that particular vertical, in that little galaxy." Recommended applications for SEOs and marketersSo some recommended applications, things that I think every SEO should probably be doing with this data. There are many, many more. I'm sure we can talk about them in the comments. 1. Identify important keywords by seeing what you rank for in the keyword universeFirst and foremost, identify keywords that you probably should be tracking, that should be part of your reporting. It will make you look good, and it will also help you keep tabs on important keywords where if you lost rankings for them, you might cost yourself a lot of traffic. Monthly granularity might not be good enough. You might want to say, "Hey, no, I want to track these keywords every week. I want to get reporting on them. I want to see which page is ranking. I want to see how I rank by geo. So I'm going to include them in my specific rank tracking features." You can do that in the Moz Keywords by Site, you'd go to Keyword Explorer, you'd select the root domain instead of the keyword, and you'd plug in your website, which maybe is Indie Hackers, a site that I've been reading a lot of lately and I like a lot.
You could see, "Oh, cool. I'm not tracking stock trading bot or ark servers, but those actually get some nice traffic. In this case, I'm ranking number 12. That's real close to page one. If I put in a little more effort on my ark servers page, maybe I could be on page one and I could be getting some of that sweet traffic, 4,000 to 6,000 searches a month. That's really significant." So great way to find additional keywords you should be adding to your tracking. 2. Discover potential keywords targets that your competitors rank for (but you don't)Second, you can discover some new potential keyword targets when you're doing keyword research based on the queries your competition ranks for that you don't. So, in this case, I might plug in "First Round." First Round Capital has a great content play that they've been doing for many years. Indie Hackers might say, "Gosh, there's a lot of stuff that startups and tech founders are interested in that First Round writes about. Let me see what keywords they're ranking for that I'm not ranking for."
So you plug in those two to Moz's tool or other tools. You could see, "Aha, I'm right. Look at that. They're ranking for about 4,500 more keywords than I am." Then I could go get that full list, and I could sort it by volume and by difficulty. Then I could choose, okay, these keywords all look good, check, check, check. Add them to my list in Keyword Explorer or Excel or Google Docs if you're using those and go to work. 3. Explore keywords sets from large, content-focused media sites with similar audiencesThen the third one is you can explore keyword sets. I'm going to urge you to. I don't think this is something that many people do, but I think that it really should be, which is to look outside of your little galaxy of yourself and your competitors, direct competitors, to large content players that serve your audience. So in this case, I might say, "Gosh, I'm Indie Hackers. I'm really competing maybe more directly with First Round. But you know what? HBR, Harvard Business Review, writes about a lot of stuff that my audience reads. I see people on Twitter that are in my audience share it a lot. I see people in our forums discussing it and linking out to their articles. Let me go see what they are doing in the content world."
In fact, when you look at the Venn diagram, which I just did in the Keywords by Site tool, I can see, "Oh my god, look there's almost no overlap, and there's this huge opportunity." So I might take HBR and I might click to see all their keywords and then start looking through and sort, again, probably by volume and maybe with a difficulty filter and say, "Which ones do I think I could create content around? Which ones do they have really old content that they haven't updated since 2010 or 2011?" Those types of content opportunities can be a golden chance for you to find an audience that is likely to be the right types of customers for your business. That's a pretty exciting thing. So, in addition to these, there's a ton of other uses. I'm sure over the next few months we'll be talking more about them here on Whiteboard Friday and here on the Moz blog. But for now, I would love to hear your uses for tools like SEMrush and the Ahrefs keyword universe feature and Moz's keyword universe feature, which is called Keywords by Site. Hopefully, we'll see you again next week for another edition of Whiteboard Friday. Take care. Video transcription by Speechpad.com Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger How to Use the "Keywords by Site" Data in Tools (Moz, SEMrush, Ahrefs, etc.) to Improve Your Keyword Research and Targeting - Whiteboard Friday Posted by John.Reinesch Competitive analysis is a key aspect when in the beginning stages of an SEO campaign. Far too often, I see organizations skip this important step and get right into keyword mapping, optimizing content, or link building. But understanding who our competitors are and seeing where they stand can lead to a far more comprehensive understanding of what our goals should be and reveal gaps or blind spots. By the end of this analysis, you will understand who is winning organic visibility in the industry, what keywords are valuable, and which backlink strategies are working best, all of which can then be utilized to gain and grow your own site’s organic traffic. Why competitive analysis is importantSEO competitive analysis is critical because it gives data about which tactics are working in the industry we are in and what we will need to do to start improving our keyword rankings. The insights gained from this analysis help us understand which tasks we should prioritize and it shapes the way we build out our campaigns. By seeing where our competitors are strongest and weakest, we can determine how difficult it will be to outperform them and the amount of resources that it will take to do so. Identify your competitorsThe first step in this process is determining who are the top four competitors that we want to use for this analysis. I like to use a mixture of direct business competitors (typically provided by my clients) and online search competitors, which can differ from whom a business identifies as their main competitors. Usually, this discrepancy is due to local business competitors versus those who are paying for online search ads. While your client may be concerned about the similar business down the street, their actual online competitor may be a business from a neighboring town or another state. To find search competitors, I simply enter my own domain name into SEMrush, scroll down to the “Organic Competitors” section, and click “View Full Report.”
The main metrics I use to help me choose competitors are common keywords and total traffic. Once I've chosen my competitors for analysis, I open up the Google Sheets Competitor Analysis Template to the “Audit Data” tab and fill in the names and URLs of my competitors in rows 2 and 3. Use the Google Sheets Competitor Analysis TemplateA clear, defined process is critical not only for getting repeated results, but to scale efforts as you start doing this for multiple clients. We created our Competitor Analysis Template so that we can follow a strategic process and focus more on analyzing the results rather than figuring out what to look for anew each time. In the Google Sheets Template, I've provided you with the data points that we'll be collecting, the tools you'll need to do so, and then bucketed the metrics based on similar themes. The data we're trying to collect relates to SEO metrics like domain authority, how much traffic the competition is getting, which keywords are driving that traffic, and the depth of competitors’ backlink profiles. I have built in a few heatmaps for key metrics to help you visualize who's the strongest at a glance.
This template is meant to serve as a base that you can alter depending on your client’s specific needs and which metrics you feel are the most actionable or relevant. Backlink gap analysisA backlink gap analysis aims to tell us which websites are linking to our competitors, but not to us. This is vital data because it allows us to close the gap between our competitors’ backlink profiles and start boosting our own ranking authority by getting links from websites that already link to competitors. Websites that link to multiple competitors (especially when it is more than three competitors) have a much higher success rate for us when we start reaching out to them and creating content for guest posts. In order to generate this report, you need to head over to the Moz Open Site Explorer tool and input the first competitor’s domain name. Next, click “Linking Domains” on the left side navigation and then click “Request CSV” to get the needed data.
Next, head to the SEO Competitor Analysis Template, select the “Backlink Import - Competitor 1” tab, and paste in the content of the CSV file. It should look like this:
Repeat this process for competitors 2–4 and then for your own website in the corresponding tabs marked in red. Once you have all your data in the correct import tabs, the “Backlink Gap Analysis” report tab will populate. The result is a highly actionable report that shows where your competitors are getting their backlinks from, which ones they share in common, and which ones you don’t currently have.
It’s also a good practice to hide all of the “Import” tabs marked in red after you paste the data into them, so the final report has a cleaner look. To do this, just right-click on the tabs and select “Hide Sheet,” so the report only shows the tabs marked in blue and green. For our clients, we typically gain a few backlinks at the beginning of an SEO campaign just from this data alone. It also serves as a long-term guide for link building in the months to come as getting links from high-authority sites takes time and resources. The main benefit is that we have a starting point full of low-hanging fruit from which to base our initial outreach. Keyword gap analysisKeyword gap analysis is the process of determining which keywords your competitors rank well for that your own website does not. From there, we reverse-engineer why the competition is ranking well and then look at how we can also rank for those keywords. Often, it could be reworking metadata, adjusting site architecture, revamping an existing piece of content, creating a brand-new piece of content specific to a theme of keywords, or building links to your content containing these desirable keywords. To create this report, a similar process as the backlink gap analysis one is followed; only the data source changes. Go to SEMrush again and input your first competitor’s domain name. Then, click on the “Organic Research” positions report in the left-side navigation menu and click on "Export" on the right.
Once you download the CSV file, paste the content into the “Keyword Import - Competitor 1” tab and then repeat the process for competitors 2–4 and your own website. The final report will now populate on the “Keyword Gap Analysis” tab marked in green. It should look like the one below:
This data gives us a starting point to build out complex keyword mapping strategy documents that set the tone for our client campaigns. Rather than just starting keyword research by guessing what we think is relevant, we have hundreds of keywords to start with that we know are relevant to the industry. Our keyword research process then aims to dive deeper into these topics to determine the type of content needed to rank well. This report also helps drive our editorial calendar, since we often find keywords and topics where we need to create new content to compete with our competitors. We take this a step further during our content planning process, analyzing the content the competitors have created that is already ranking well and using that as a base to figure out how we can do it better. We try to take some of the best ideas from all of the competitors ranking well to then make a more complete resource on the topic. Using key insights from the audit to drive your SEO strategyIt is critically important to not just create this report, but also to start taking action based on the data that you have collected. On the first tab of the spreadsheet template, we write in insights from our analysis and then use those insights to drive our campaign strategy. Some examples of typical insights from this document would be the average number of referring domains that our competitors have and how that relates to our own backlink profile. If we are ahead of our competitors regarding backlinks, content creation might be the focal point of the campaign. If we are behind our competitors in regards to backlinks, we know that we need to start a link building campaign as soon as possible. Another insight we gain is which competitors are most aggressive in PPC and which keywords they are bidding on. Often, the keywords that they are bidding on have high commercial intent and would be great keywords to target organically and provide a lift to our conversions. Start implementing competitive analyses into your workflowCompetitive analyses for SEO are not something that should be overlooked when planning a digital marketing strategy. This process can help you strategically build unique and complex SEO campaigns based on readily available data and the demand of your market. This analysis will instantly put you ahead of competitors who are following cookie-cutter SEO programs and not diving deep into their industry. Start implementing this process as soon as you can and adjust it based on what is important to your own business or client’s business. Don’t forget to make a copy of the spreadsheet template here: Get the Competitive Analysis Template Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger How to Do a Competitor Analysis for SEO Tangential Content Earns More Links and Social Shares in Boring Industries [New Research]10/24/2017 Posted by kerryjones Many companies still don’t see the benefit of creating content that isn’t directly about their products or brand. But unless you have a universally interesting brand, you’ll be hard-pressed to attract much of an audience if all you do is publish brand-centric content. Content marketing is meant to solve this dilemma. By offering genuinely useful content to your target customers, rather than selling to them, you earn their attention and over time gain their trust. And yet, I find myself explaining the value of non-branded content all too often. I frequently hear grumblings from fellow marketers that clients and bosses refuse to stray from sales-focused content. I see companies publishing what are essentially advertorials and calling it content marketing.
In addition to turning off customers, branded content can be extremely challenging for building links or earning PR mentions. If you’ve ever done outreach for branded content, you’ve probably gotten a lot of pushback from the editors and writers you’ve pitched. Why? Most publishers bristle at content that feels like a brand endorsement pretending not to be a brand endorsement (and expect you to pay big bucks for a sponsored content or native advertising spot). Fortunately, there’s a type of content that can earn your target customers’ attention, build high-quality links, and increase brand awareness... Tangential content: The cure for a boring nicheAt Fractl, we refer to content on a topic that’s related to (but not directly about) the brand that created it as "tangential content." Some hypothetical examples of tangential content would be:
While there’s a time for branded content further down the sales funnel, tangential content might be right for you if you want to:
Comparison of tangential vs. on-brand content performanceIn our experience at Fractl, tangential content has been highly effective for link building campaigns, especially in narrow client niches that lack broad appeal. While we’ve assumed this is true based on our observations, we now have the data to back up our assumption. We recently categorized 835 Fractl client campaigns as either “tangential” or “on-brand,” then compared the average number of pickups (links and press mentions) and number of social shares for each group. Our hunch was right: The tangential campaigns earned 30% more media mentions and 77% more social shares on average than the brand-focused campaigns.
So what exactly does a tangential campaign look like? Below are some real examples of our client campaigns that illustrate how tangential topics can yield stellar results. Most Hateful/Most Politically Correct Places
Why it workedAfter a string of on-brand campaigns for this client yielded average results, we knew capitalizing on a hot-button, current issue would attract tons of attention. This topic still ties back into the client’s main objective of helping people find a home since the community and location of that home are important factors in one’s decisions. Check out the full case study of this campaign for more insights into why it was successful. Most Instagrammed Locations
Why it workedOur client’s niche, bus travel, had a limited audience, so we chose a topic that was of interest to anyone who enjoys traveling, regardless of the mode of transportation they use to get there. By incorporating data from a popular social network and using an idea with a strong geographic focus, we could target a lot of different groups — the campaign appealed to travel enthusiasts, Instagram users, and regional and city news outlets (including TV stations). For more details about our thought process behind this idea, see the campaign case study. Most Attractive NFL Players and Teams
Client niche: Sports apparel retailer Campaign topic: Survey that rates the most attractive NFL players Results: 45,000+ social shares and 247 media pickups, including CBS Sports, USA Today, Fox Sports, and NFL.com Why it workedSince diehard fans want to show off that their favorite player is the best, even if it’s just in the looks department, we were confident this lighthearted campaign would pique fan interest. But fans weren’t the only ones hitting the share button — the campaign also grabbed the attention of the featured teams and players, with many sharing on their social media profiles, which helped drive exposure.
On-brand content works best in certain verticalsTangential content isn’t always necessary for earning top-of-funnel awareness. So, how do you know if your brand-centric topics will garner lots of interest? A few things to consider:
We’ve seen several industry verticals perform very well using branded content. When we broke down our campaign data by vertical, we found our top performing on-brand campaign topics were technology, drugs and alcohol, and marketing.
Some examples of our successful on-brand campaign topics include:
Coming up with tangential content ideasOnce you free yourself from only brainstorming brand-centric ideas, you might find it easy to dream up tangential concepts. If you need a little help, here are a few tips to get you started: Review your buyer personas.In order to know which tangential topics to choose, you need to understand your target audience’s interests and where your niche intersects with those interests. The best way to find this information? Buyer personas. If you don’t already have detailed buyer personas built out, Mike King’s epic Moz post from a few years ago remains the bible on personas in my opinion. Find topics your audience cares about with Facebook Audience Insights.Using its arsenal of user data, this Facebook ads tool gives you a peek into the interests and lifestyles of your target audience. These insights can supplement and inform your buyer personas. See the incredibly actionable post “How to Create Buyer Personas on a Budget Using Facebook Audience Insights” for more help with leveraging this tool. Consider how trending news topics are tangential to your brand.Pay attention to themes that keep popping up in the news and how your brand relates back to these stories (this is how the most racist/bigoted states and cities campaign I mentioned earlier in this post came to be). Also anticipate seasonal or event-based topics that are tangential to your brand. For example, a tire manufacturer may want to create content on protecting your car from flooding and storm damage during hurricane season. Test tangential concepts on social media.Not sure if a tangential topic will go over well? Before moving forward with a big content initiative, test it out by sharing content related to the topic on your brand’s social media accounts. Does it get a good reaction? Pro tip: spend a little bit of money promoting these as sponsored posts to ensure they get in front of your followers. Have you had success creating content outside of your brand niche? I’d love to hear about your tangential content examples and the results you achieved, please share in the comments! Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger Tangential Content Earns More Links and Social Shares in Boring Industries [New Research] Posted by randfish For many years now, Moz's customers and so, so many of my friends and colleagues in the SEO world have had one big feature request from our toolset: "GIVE ME KEYWORDS BY SITE!" Today, we're answering that long-standing request with that precise data inside
This data is likely familiar to folks who've used tools like SEMRush, KeywordSpy, Spyfu, or others, and we have a few areas we think are stronger than these competitors, and a few known areas of weakness (I'll get to both in a minute). For those who aren't familiar with this type of data, it offers a few big, valuable solutions for marketers and SEOs of all kinds. You can:
My top favorite features in this new release are: #1 - The clear, useful comparison data between sites or pages
Comparing the volume of a site's ranking keywords is a really powerful way to show how, even when there's a strong site in a space (like Sleepopolis in the mattress reviews world), they are often losing out in the mid-long tail of rankings, possibly because they haven't targeted the quantity of keywords that their competitors have. This type of crystal-clear interface (powerful enough to be used by experts, but easily understandable to anyone) really impressed me when I saw it. Bravo to Moz's UI folks for nailing it. #2 - The killer Venn diagram showing keyword overlaps
Aww yeah! I love this interactive venn diagram of the ranking keywords, and the ability to see the quantity of keywords for each intersection at a glance. I know I'll be including screenshots like this in a lot of the analyses I do for friends, startups, and non-profits I help with SEO. #3 - The accuracy & recency of the ranking, volume, & difficulty data
As you'll see in the comparison below, Moz's keyword universe is technically smaller than some others. But I love the trustworthiness of the data in this tool. We refresh not only rankings, but keyword volume data multiple times every month (no dig on competitors, but when volume or rankings data is out of date, it's incredibly frustrating, and lessens the tool's value for me). That means I can use and rely on the metrics and the keyword list — when I go to verify manually, the numbers and the rankings match. That's huge. Caveat: Any rankings that are personalized or geo-biased tend to have some ranking position changes or differences. If you're doing a lot of geographically sensitive rankings research, it's still best to use a rank tracking solution like the one in Moz Pro Campaigns (or, at an enterprise level, a tool like STAT). How does Moz's keyword universe stack up to the competition? We're certainly the newest player in this particular space, but we have some advantages over the other players (and, to be fair, some drawbacks too). Moz's Russ Jones put together this data to help compare:
Click the image for a larger version Obviously, we've made the decision to be generally smaller, but fresher, than most of our competitors. We do this because:
Over time, we hope to grow our corpus (so long as we can maintain accuracy and freshness, which provide the advantages above), and extend to other geographies as well. If you're a Moz Pro subscriber and haven't tried out this feature yet, give it a spin. To explore keywords by site, simply enter a root domain, subdomain, or exact page into the universal search bar in Keyword Explorer. Use the drop if you need to modify your search (for example, researching a root domain as a keyword). There's immense value to be had here, and a wealth of powerful, accurate, timely rankings data that can help boost your SEO targeting and competitive research efforts. I'm looking forward to your comments, questions, and feedback! Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger NEW in Keyword Explorer: See Who Ranks & How Much with Keywords by Site Posted by randfish Which link is more valuable: the one in your nav, or the one in the content of your page? Now, how about if one of those in-content links is an image, and one is text? Not all links are created equal, and getting familiar with the details will help you build a stronger linking structure.
Click on the whiteboard image above to open a high-resolution version in a new tab! <span id="selection-marker-1" class="redactor-selection-marker"></span>Video TranscriptionHowdy, Moz fans, and welcome to another edition of Whiteboard Friday. This week we're going to chat about links in headers and footers, in navigation versus content, and how that can affect both internal and external links and the link equity and link value that they pass to your website or to another website if you're linking out to them.
So I'm going to use Candy Japan here. They recently crossed $1 million in sales. Very proud of Candy Japan. They sell these nice boxes of random assortments of Japanese candy that come to your house. Their website is actually remarkably simplistic. They have some footer links. They have some links in the content, but not a whole lot else. But I'm going to imagine them with a few more links in here just for our purposes. It turns out that there are a number of interesting items when it comes to internal linking. So, for example, some on-page links matter more and carry more weight than other kinds. If you are smart and use these across your entire site, you can get some incremental or potentially some significant benefits depending on how you do it. Do some on-page links matter more than others?So, first off, good to know that... I. Content links tend to matter more...just broadly speaking, than navigation links. That shouldn't be too surprising, right? If I have a link down here in the content of the page pointing to my Choco Puffs or my Gummies page, that might actually carry more weight in Google's eyes than if I point to it in my navigation. Now, this is not universally true, but observably, it seems to be the case. So when something is in the navigation, it's almost always universally in that navigation. When something is in here, it's often only specifically in here. So a little tough to tell cause and effect, but we can definitely see this when we get to external links. I'll talk about that in a sec. II. Links in footers often get devaluedSo if there's a link that you've got in your footer, but you don't have it in your primary navigation, whether that's on the side or the top, or in the content of the page, a link down here may not carry as much weight internally. In fact, sometimes it seems to carry almost no weight whatsoever other than just the indexing. III. More used links may carry more weightThis is a theory for now. But we've seen some papers on this, and there has been some hypothesizing in the SEO community that essentially Google is watching as people browse the web, and they can get that data and sort of see that, hey, this is a well-trafficked page. It gets a lot of visits from this other page. This navigation actually seems to get used versus this other navigation, which doesn't seem to be used. There are a lot of ways that Google might interpret that data or might collect it. It could be from the size of it or the CSS qualities. It could be from how it appears on the page visually. But regardless, that also seems to be the case. IV. Most visible links may get more weightThis does seem to be something that's testable. So if you have very small fonts, very tiny links, they are not nearly as accessible or obvious to visitors. It seems to be the case that they also don't carry as much weight in Google's rankings. V. On pages with multiple links to the same URLFor example, let's say I've got this products link up here at the top, but I also link to my products down here under Other Candies, etc. It turns out that Google will see both links. They both point to the same page in this case, both pointing to the same page over here, but this page will only inherit the value of the anchor text from the first link on the page, not both of them. So Other Candies, etc., that anchor text will essentially be treated as though it doesn't exist. Google ignores multiple links to the same URL. This is actually true internal and external. For this reason, if you're going ahead and trying to stuff in links in your internal content to other pages, thinking that you can get better anchor text value, well look, if they're already in your navigation, you're not getting any additional value. Same case if they're up higher in the content. The second link to them is not carrying the anchor text value. Can link location/type affect external link impact?Other items to note on the external side of things and where they're placed on pages. I. In-content links are going to be more valuable than footers or nav linksIn general, nav links are going to do better than footers. But in content, this primary content area right in here, that is where you're going to get the most link value if you have the option of where you're going to get an external link from on a page. II. What if you have links that open in a new tab or in a new window versus links that open in the same tab, same window?It doesn't seem to matter at all. Google does not appear to carry any different weight from the experiments that we've seen and the ones we've conducted. III. Text links do seem to perform better, get more weight than image links with alt attributesThey also seem to perform better than JavaScript links and other types of links, but critically important to know this, because many times what you will see is that a website will do something like this. They'll have an image. This image will be a link that will point off to a page, and then below it they'll have some sort of caption with keyword-rich anchors down here, and that will also point off. But Google will treat this first link as though it is the one, and it will be the alt attribute of this image that passes the anchor text, unless this is all one href tag, in which case you do get the benefit of the caption as the anchor. So best practice there. IV. Multiple links from same page — only the first anchor countsWell, just like with internal links, only the first anchor is going to count. So if I have two links from Candy Japan pointing to me, it's only the top one that Google sees first in the HTML. So it's not where it's organized in the site as it renders visually, but where it comes up in the HTML of the page as Google is rendering that. V. The same link and anchor on many or most or all pages on a website tends to get you into trouble.Not always, not universally. Sometimes it can be okay. Is Amazon allowed to link to Whole Foods from their footer? Yes, they are. They're part of the same company and group and that kind of thing. But if, for example, Amazon were to go crazy spamming and decided to make it "cheap avocados delivered to your home" and put that in the footer of all their pages and point that to the WholeFoods.com/avocadodelivery page, that would probably get penalized, or it may just be devalued. It might not rank at all, or it might not pass any link equity. So notable that in the cases where you have the option of, "Should I get a link on every page of a website? Well, gosh, that sounds like a good deal. I'd pass all this page rank and all this link equity." No, bad deal. Instead, far better would be to get a link from a page that's already linked to by all of these pages, like, hey, if we can get a link from the About page or from the Products page or from the homepage, a link on the homepage, those are all great places to get links. I don't want a link on every page in the footer or on every page in a sidebar. That tends to get me in trouble, especially if it is anchor text-rich and clearly keyword targeted and trying to manipulate SEO. All right, everyone. I look forward to your questions. We'll see you again next week for another edition of Whiteboard Friday. Take care. Video transcription by Speechpad.com Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger How Links in Headers, Footers, Content, and Navigation Can Impact SEO - Whiteboard Friday Posted by alexis-sanders Schema.org is cryptic. Or at least that’s what I had always thought. To me, it was a confusing source of information: missing the examples I needed, not explaining which item properties search engines require, and overall making the process of implementing structured data a daunting task. However, once I got past Schema.org’s intimidating shell, I found an incredibly useful and empowering tool. Once you know how to leverage it, Schema.org is an indispensable tool within your SEO toolbox.
A structured data toolboxThe first part of any journey is finding the map. In terms of structured data, there are a few different guiding resources:
As an example, I’m going to walk through the Aquarium item type Schema.org markup. For illustrative purposes, I’m going to stick with JSON-LD moving forward; however, if there are any microdata questions, please reach out in the comments. Basic structure of all Schema.org pagesWhen you first enter a Schema.org item type’s page, notice that every page has the same layout, starting with the item type name, the canonical reference URL (currently the HTTP version*), where the markup lives within the Schema.org hierarchy, and that item type’s usage on the web.
*Leveraging the HTTPS version of a Schema.org markup is acceptable What is an item type?An item type is a piece of Schema.org’s vocabulary of data used to annotate and structure elements on a web page. You can think about it as what you’re marking up. At the highest level of most Schema.org item types is Thing (alternatively, we’d be looking at DataType). This intuitively makes sense because almost everything is, at its highest level of abstraction, a Thing. The item type Thing has multiple children, all of which assume Thing’s properties in a cascading in a hierarchical fashion (i.e., a Product is a Thing, both can have names, descriptions, and images). Explore Schema.org’s item types here with the various visualizations:
https://technicalseo.com/seo-tools/schema-markup-generator/visual/ Item types are going to be the first attribute in your markup and will look a little like this (remember this for a little later):
Tip: Every Schema.org item type can be found by typing its name after Schema.org, i.e. http://schema.org/Aquarium (note that case is important). Below, this is where things start to get fun — the properties, expected type, and description of each property.
What are item properties?Item properties are attributes, which describe item types (i.e., it’s a property of the item). All item properties are inherited from the parent item type. The value of the property can be a word, URL, or number.
What is the "Expected Type"?For every item type, there is a column the defines the expected item type of each item property. This is a signal which tells us whether or not nesting will be involved. If the expected property is a data type (i.e., text, number, etc.) you will not have to do anything; otherwise get ready for some good, old-fashioned nesting. One of the things you may have noticed: under “Property” it says “Properties from CivicStructure.” We know that an Aquarium is a child of CivicStructure, as it is listed above. If we scan the page, we see the following “Properties from…”:
This looks strikingly like the hierarchy listed above and it is (just vertical… and backward). Only one thing is missing – where are the “Properties from Aquarium”? The answer is actually quite simple — Aquarium has no item properties of its own. Therefore, CivilStructures (being the next most specific item type with properties) is listed first. Structuring this information with more specific properties at the top makes a ton of sense intuitively. When marking up information, we are typically interested in the most specific item properties, ones that are closest conceptually to the thing we’re marking up. These properties are generally the most relevant. Creating a markup
Side notes:
TL;DR:
Thanks! A huge thanks to Max Prin (@maxxeight), Adam Audette (@audette), and the @MerkleCRM team for reviewing this article. Plus, shout outs to Max (again), Steve Valenza (#TwitterlessSteve), and Eric Hammond (@elhammond) for their work, ideas, and thought leadership that went into the Schema Generator Tool! Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger Unlocking Hidden Gems Within Schema.org Posted by goralewicz Crawling and indexing has been a hot topic over the last few years. As soon as Google launched Google Panda, people rushed to their server logs and crawling stats and began fixing their index bloat. All those problems didn’t exist in the “SEO = backlinks” era from a few years ago. With this exponential growth of technical SEO, we need to get more and more technical. That being said, we still don’t know how exactly Google crawls our websites. Many SEOs still can’t tell the difference between crawling and indexing. The biggest problem, though, is that when we want to troubleshoot indexing problems, the only tool in our arsenal is Google Search Console and the Fetch and Render tool. Once your website includes more than HTML and CSS, there's a lot of guesswork into how your content will be indexed by Google. This approach is risky, expensive, and can fail multiple times. Even when you discover the pieces of your website that weren’t indexed properly, it's extremely difficult to get to the bottom of the problem and find the fragments of code responsible for the indexing problems. Fortunately, this is about to change. Recently, Ilya Grigorik from Google shared one of the most valuable insights into how crawlers work:
Interestingly, this tweet didn’t get nearly as much attention as I would expect. So what does Ilya’s revelation in this tweet mean for SEOs?Knowing that Chrome 41 is the technology behind the Web Rendering Service is a game-changer. Before this announcement, our only solution was to use Fetch and Render in Google Search Console to see our page rendered by the Website Rendering Service (WRS). This means we can troubleshoot technical problems that would otherwise have required experimenting and creating staging environments. Now, all you need to do is download and install Chrome 41 to see how your website loads in the browser. That’s it. You can check the features and capabilities that Chrome 41 supports by visiting Caniuse.com or Chromestatus.com (Googlebot should support similar features). These two websites make a developer’s life much easier. Even though we don’t know exactly which version Ilya had in mind, we can find Chrome’s version used by the WRS by looking at the server logs. It’s Chrome 41.0.2272.118.
It will be updated sometime in the futureChrome 41 was created two years ago (in 2015), so it’s far removed from the current version of the browser. However, as Ilya Grigorik said, an update is coming:
I was lucky enough to get Ilya Grigorik to read this article before it was published, and he provided a ton of valuable feedback on this topic. He mentioned that they are hoping to have the WRS updated by 2018. Fingers crossed! Google uses Chrome 41 for rendering. What does that mean?We now have some interesting information about how Google renders websites. But what does that mean, practically, for site developers and their clients? Does this mean we can now ignore server-side rendering and deploy client-rendered, JavaScript-rich websites? Not so fast. Here is what Ilya Grigorik had to say in response to this question:
We now know WRS' capabilities for rendering JavaScript and how to debug them. However, remember that not all crawlers support Javascript crawling, etc. Also, as of today, JavaScript crawling is only supported by Google and Ask (Ask is most likely powered by Google). Even if you don’t care about social media or search engines other than Google, one more thing to remember is that even with Chrome 41, not all JavaScript frameworks can be indexed by Google (read more about JavaScript frameworks crawling and indexing). This lets us troubleshoot and better diagnose problems. Don’t get your hopes upAll that said, there are a few reasons to keep your excitement at bay. Remember that version 41 of Chrome is over two years old. It may not work very well with modern JavaScript frameworks. To test it yourself, open http://jsseo.expert/polymer/ using Chrome 41, and then open it in any up-to-date browser you are using. The page in Chrome 41 looks like this:
The content parsed by Polymer is invisible (meaning it wasn’t processed correctly). This is also a perfect example for troubleshooting potential indexing issues. The problem you're seeing above can be solved if diagnosed properly. Let me quote Ilya: "If you look at the raised Javascript error under the hood, the test page is throwing an error due to unsupported (in M41) ES6 syntax. You can test this yourself in M41, or use the debug snippet we provided in the blog post to log the error into the DOM to see it." I believe this is another powerful tool for web developers willing to make their JavaScript websites indexable. We will definitely expand our experiment and work with Ilya’s feedback. The Fetch and Render tool is the Chrome v. 41 previewThere's another interesting thing about Chrome 41. Google Search Console's Fetch and Render tool is simply the Chrome 41 preview. The righthand-side view (“This is how a visitor to your website would have seen the page") is generated by the Google Search Console bot, which is... Chrome 41.0.2272.118 (see screenshot below).
There's evidence that both Googlebot and Google Search Console Bot render pages using Chrome 41. Still, we don’t exactly know what the differences between them are. One noticeable difference is that the Google Search Console bot doesn’t respect the robots.txt file. There may be more, but for the time being, we're not able to point them out. Chrome 41 vs Fetch as Google: A word of cautionChrome 41 is a great tool for debugging Googlebot. However, sometimes (not often) there's a situation in which Chrome 41 renders a page properly, but the screenshots from Google Fetch and Render suggest that Google can’t handle the page. It could be caused by CSS animations and transitions, Googlebot timeouts, or the usage of features that Googlebot doesn’t support. Let me show you an example. Chrome 41 preview:
Image blurred for privacy The above page has quite a lot of content and images, but it looks completely different in Google Search Console. Google Search Console preview for the same URL:
As you can see, Google Search Console’s preview of this URL is completely different than what you saw on the previous screenshot (Chrome 41). All the content is gone and all we can see is the search bar. From what we noticed, Google Search Console renders CSS a little bit different than Chrome 41. This doesn’t happen often, but as with most tools, we need to double check whenever possible. This leads us to a question... What features are supported by Googlebot and WRS?According to the Rendering on Google Search guide:
The last point is really interesting. Despite statements from Google over the last 2 years, Google still only crawls using HTTP/1.1. No HTTP/2 support (still)We've mostly been covering how Googlebot uses Chrome, but there's another recent discovery to keep in mind. There is still no support for HTTP/2 for Googlebot. Since it's now clear that Googlebot doesn’t support HTTP/2, this means that if your website supports HTTP/2, you can’t drop HTTP 1.1 optimization. Googlebot can crawl only using HTTP/1.1. There were several announcements recently regarding Google’s HTTP/2 support. To read more about it, check out my HTTP/2 experiment here on the Moz Blog.
Via https://developers.google.com/search/docs/guides/r... Googlebot’s futureRumor has it that Chrome 59’s headless mode was created for Googlebot, or at least that it was discussed during the design process. It's hard to say if any of this chatter is true, but if it is, it means that to some extent, Googlebot will “see” the website in the same way as regular Internet users. This would definitely make everything simpler for developers who wouldn’t have to worry about Googlebot’s ability to crawl even the most complex websites. Chrome 41 vs. Googlebot’s crawling efficiencyChrome 41 is a powerful tool for debugging JavaScript crawling and indexing. However, it's crucial not to jump on the hype train here and start launching websites that “pass the Chrome 41 test.” Even if Googlebot can “see” our website, there are many other factors that will affect your site’s crawling efficiency. As an example, we already have proof showing that Googlebot can crawl and index JavaScript and many JavaScript frameworks. It doesn’t mean that JavaScript is great for SEO. I gathered significant evidence showing that JavaScript pages aren’t crawled even half as effectively as HTML-based pages. In summaryIlya Grigorik’s tweet sheds more light on how Google crawls pages and, thanks to that, we don’t have to build experiments for every feature we're testing — we can use Chrome 41 for debugging instead. This simple step will definitely save a lot of websites from indexing problems, like when Hulu.com’s JavaScript SEO backfired. It's safe to assume that Chrome 41 will now be a part of every SEO’s toolset. Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger Google Shares Details About the Technology Behind Googlebot Posted by goralewicz I was recently challenged with a question from a client, Robert, who runs a small PR firm and needed to optimize a client’s website. His question inspired me to run a small experiment in HTTP protocols. So what was Robert’s question? He asked... Can Googlebot crawl using HTTP/2 protocols? You may be asking yourself, why should I care about Robert and his HTTP protocols?As a refresher, HTTP protocols are the basic set of standards allowing the World Wide Web to exchange information. They are the reason a web browser can display data stored on another server. The first was initiated back in 1989, which means, just like everything else, HTTP protocols are getting outdated. HTTP/2 is one of the latest versions of HTTP protocol to be created to replace these aging versions. So, back to our question: why do you, as an SEO, care to know more about HTTP protocols? The short answer is that none of your SEO efforts matter or can even be done without a basic understanding of HTTP protocol. Robert knew that if his site wasn’t indexing correctly, his client would miss out on valuable web traffic from searches. The hype around HTTP/2HTTP/1.1 is a 17-year-old protocol (HTTP 1.0 is 21 years old). Both HTTP 1.0 and 1.1 have limitations, mostly related to performance. When HTTP/1.1 was getting too slow and out of date, Google introduced SPDY in 2009, which was the basis for HTTP/2. Side note: Starting from Chrome 53, Google decided to stop supporting SPDY in favor of HTTP/2. HTTP/2 was a long-awaited protocol. Its main goal is to improve a website’s performance. It's currently used by 17% of websites (as of September 2017). Adoption rate is growing rapidly, as only 10% of websites were using HTTP/2 in January 2017. You can see the adoption rate charts here. HTTP/2 is getting more and more popular, and is widely supported by modern browsers (like Chrome or Firefox) and web servers (including Apache, Nginx, and IIS). Its key advantages are:
For more information, I highly recommend reading “Introduction to HTTP/2” by Surma and Ilya Grigorik. All these benefits suggest pushing for HTTP/2 support as soon as possible. However, my experience with technical SEO has taught me to double-check and experiment with solutions that might affect our SEO efforts. So the question is: Does Googlebot support HTTP/2? Google's promisesHTTP/2 represents a promised land, the technical SEO oasis everyone was searching for. By now, many websites have already added HTTP/2 support, and developers don’t want to optimize for HTTP/1.1 anymore. Before I could answer Robert’s question, I needed to know whether or not Googlebot supported HTTP/2-only crawling. I was not alone in my query. This is a topic which comes up often on Twitter, Google Hangouts, and other such forums. And like Robert, I had clients pressing me for answers. The experiment needed to happen. Below I'll lay out exactly how we arrived at our answer, but here’s the spoiler: it doesn't. Google doesn’t crawl using the HTTP/2 protocol. If your website uses HTTP/2, you need to make sure you continue to optimize the HTTP/1.1 version for crawling purposes. The questionIt all started with a Google Hangouts in November 2015. When asked about HTTP/2 support, John Mueller mentioned that HTTP/2-only crawling should be ready by early 2016, and he also mentioned that HTTP/2 would make it easier for Googlebot to crawl pages by bundling requests (images, JS, and CSS could be downloaded with a single bundled request). "At the moment, Google doesn’t support HTTP/2-only crawling (...) We are working on that, I suspect it will be ready by the end of this year (2015) or early next year (2016) (...) One of the big advantages of HTTP/2 is that you can bundle requests, so if you are looking at a page and it has a bunch of embedded images, CSS, JavaScript files, theoretically you can make one request for all of those files and get everything together. So that would make it a little bit easier to crawl pages while we are rendering them for example." Soon after, Twitter user Kai Spriestersbach also asked about HTTP/2 support: His clients started dropping HTTP/1.1 connections optimization, just like most developers deploying HTTP/2, which was at the time supported by all major browsers.
After a few quiet months, Google Webmasters reignited the conversation, tweeting that Google won’t hold you back if you're setting up for HTTP/2. At this time, however, we still had no definitive word on HTTP/2-only crawling. Just because it won't hold you back doesn't mean it can handle it — which is why I decided to test the hypothesis.
The experimentFor months as I was following this online debate, I still received questions from our clients who no longer wanted want to spend money on HTTP/1.1 optimization. Thus, I decided to create a very simple (and bold) experiment. I decided to disable HTTP/1.1 on my own website (https://goralewicz.com) and make it HTTP/2 only. I disabled HTTP/1.1 from March 7th until March 13th. 
If you’re going to get bad news, at the very least it should come quickly. I didn’t have to wait long to see if my experiment “took.” Very shortly after disabling HTTP/1.1, I couldn’t fetch and render my website in Google Search Console; I was getting an error every time.
My website is fairly small, but I could clearly see that the crawling stats decreased after disabling HTTP/1.1. Google was no longer visiting my site.
While I could have kept going, I stopped the experiment after my website was partially de-indexed due to “Access Denied” errors.
The resultsI didn’t need any more information; the proof was right there. Googlebot wasn’t supporting HTTP/2-only crawling. Should you choose to duplicate this at home with our own site, you’ll be happy to know that my site recovered very quickly. I finally had Robert’s answer, but felt others may benefit from it as well. A few weeks after finishing my experiment, I decided to ask John about HTTP/2 crawling on Twitter and see what he had to say.
(I love that he responds.)
Knowing the results of my experiment, I have to agree with John: disabling HTTP/1 was a bad idea. However, I was seeing other developers discontinuing optimization for HTTP/1, which is why I wanted to test HTTP/2 on its own. For those looking to run their own experiment, there are two ways of negotiating a HTTP/2 connection: 1. Over HTTP (unsecure) – Make an HTTP/1.1 request that includes an Upgrade header. This seems to be the method to which John Mueller was referring. However, it doesn't apply to my website (because it’s served via HTTPS). What is more, this is an old-fashioned way of negotiating, not supported by modern browsers. Below is a screenshot from Caniuse.com:
2. Over HTTPS (secure) – Connection is negotiated via the ALPN protocol (HTTP/1.1 is not involved in this process). This method is preferred and widely supported by modern browsers and servers. A recent announcement: The saga continuesGooglebot doesn’t make HTTP/2 requestsFortunately, Ilya Grigorik, a web performance engineer at Google, let everyone peek behind the curtains at how Googlebot is crawling websites and the technology behind it:
If that wasn’t enough, Googlebot doesn't support the WebSocket protocol. That means your server can’t send resources to Googlebot before they are requested. Supporting it wouldn't reduce network latency and round-trips; it would simply slow everything down. Modern browsers offer many ways of loading content, including WebRTC, WebSockets, loading local content from drive, etc. However, Googlebot supports only HTTP/FTP, with or without Transport Layer Security (TLS). Googlebot supports SPDYDuring my research and after John Mueller’s feedback, I decided to consult an HTTP/2 expert. I contacted Peter Nikolow of Mobilio, and asked him to see if there were anything we could do to find the final answer regarding Googlebot’s HTTP/2 support. Not only did he provide us with help, Peter even created an experiment for us to use. Its results are pretty straightforward: Googlebot does support the SPDY protocol and Next Protocol Navigation (NPN). And thus, it can’t support HTTP/2. Below is Peter’s response: I performed an experiment that shows Googlebot uses SPDY protocol. Because it supports SPDY + NPN, it cannot support HTTP/2. There are many cons to continued support of SPDY:
To examine Googlebot and the protocols it uses, I took advantage of s_server, a tool that can debug TLS connections. I used Google Search Console Fetch and Render to send Googlebot to my website. Here's a screenshot from this tool showing that Googlebot is using Next Protocol Navigation (and therefore SPDY):
I'll briefly explain how you can perform your own test. The first thing you should know is that you can’t use scripting languages (like PHP or Python) for debugging TLS handshakes. The reason for that is simple: these languages see HTTP-level data only. Instead, you should use special tools for debugging TLS handshakes, such as s_server. Type in the console: sudo openssl s_server -key key.pem -cert cert.pem -accept 443 -WWW -tlsextdebug -state -msg sudo openssl s_server -key key.pem -cert cert.pem -accept 443 -www -tlsextdebug -state -msg Please note the slight (but significant) difference between the “-WWW” and “-www” options in these commands. You can find more about their purpose in the s_server documentation. Next, invite Googlebot to visit your site by entering the URL in Google Search Console Fetch and Render or in the Google mobile tester. As I wrote above, there is no logical reason why Googlebot supports SPDY. This protocol is vulnerable; no modern browser supports it. Additionally, servers (including NGINX) neglect to support it. It’s just a matter of time until Googlebot will be able to crawl using HTTP/2. Just implement HTTP 1.1 + HTTP/2 support on your own server (your users will notice due to faster loading) and wait until Google is able to send requests using HTTP/2. SummaryIn November 2015, John Mueller said he expected Googlebot to crawl websites by sending HTTP/2 requests starting in early 2016. We don’t know why, as of October 2017, that hasn't happened yet. What we do know is that Googlebot doesn't support HTTP/2. It still crawls by sending HTTP/ 1.1 requests. Both this experiment and the “Rendering on Google Search” page confirm it. (If you’d like to know more about the technology behind Googlebot, then you should check out what they recently shared.) For now, it seems we have to accept the status quo. We recommended that Robert (and you readers as well) enable HTTP/2 on your websites for better performance, but continue optimizing for HTTP/ 1.1. Your visitors will notice and thank you. Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger Does Googlebot Support HTTP/2? Challenging Google's Indexing Claims – An Experiment Writing Headlines that Serve SEO Social Media and Website Visitors All Together - Whiteboard Friday10/13/2017 Posted by randfish Have your headlines been doing some heavy lifting? If you've been using one headline to serve multiple audiences, you're missing out on some key optimization opportunities. In today's Whiteboard Friday, Rand gives you a process for writing headlines for SEO, for social media, and for your website visitors — each custom-tailored to its audience and optimized to meet different goals.
Click on the whiteboard image above to open a high-resolution version in a new tab! Video TranscriptionHowdy, Moz fans, and welcome to another edition of Whiteboard Friday. This week we're going to chat about writing headlines. One of the big problems that headlines have is that they need to serve multiple audiences. So it's not just ranking and search engines. Even if it was, the issue is that we need to do well on social media. We need to serve our website visitors well in order to rank in the search engines. So this gets very challenging.
I've tried to illustrate this with a Venn diagram here. So you can see, basically... SEOIn the SEO world of headline writing, what I'm trying to do is rank well, earn high click-through rate, because I want a lot of those visitors to the search results to choose my result, not somebody else's. I want low pogo-sticking. I don't want anyone clicking the back button and choosing someone else's result because I didn't fulfill their needs. I need to earn links, and I've got to have engagement. Social mediaOn the social media side, it's pretty different actually. I'm trying to earn amplification, which can often mean the headline tells as much of the story as possible. Even if you don't read the piece, you amplify it, you retweet it, and you re-share it. I'm looking for clicks, and I'm looking for comments and engagement on the post. I'm not necessarily too worried about that back button and the selection of another item. In fact, time on site might not even be a concern at all. Website visitorsFor website visitors, both of these are channels that drive traffic. But for the site itself, I'm trying to drive right visitors, the ones who are going to be loyal, who are going to come back, hopefully who are going to convert. I want to not confuse anyone. I want to deliver on my promise so that I don't create a bad brand reputation and detract from people wanting to click on me in the future. For those of you have visited a site like Forbes or maybe even a BuzzFeed and you have an association of, "Oh, man, this is going to be that clickbait stuff. I don't want to click on their stuff. I'm going to choose somebody else in the results instead of this brand that I remember having a bad experience with." Notable conflictsThere are some notable direct conflicts in here.
Getting to resolutionSo how do we resolve this? Well, it's not actually a terribly hard process. In 2017 and beyond, what's nice is that search engines and social and visitors all have enough shared stuff that, most of the time, we can get to a good, happy resolution. Step one: Determine who your primary audience is, your primary goals, and some prioritization of those channels.You might say, "Hey, this piece is really targeted at search. If it does well on social, that's fine, but this is going to be our primary traffic driver." Or you might say, "This is really for internal website visitors who are browsing around our site. If it happens to drive some traffic from search or social, well that's fine, but that's not our intent." Step two: For non-conflict elements, optimize for the most demanding channel.For those non-conflicting elements, so this could be the page title that you use for SEO, it doesn't always have to perfectly match the headline. If it's a not-even-close match, that's a real problem, but an imperfect match can still be okay. So what's nice in social is you have things like Twitter cards and the Facebook markup, graph markup. That Open Graph markup means that you can have slightly different content there than what you might be using for your snippet, your meta description in search engines. So you can separate those out or choose to keep those distinct, and that can help you as well. Step three: Author the straightforward headline first.I'm going to ask you author the most straightforward version of the headline first. Step four: Now write the social-friendly/click-likely version without other considerations.Is to write the opposite of that, the most social-friendly or click-likely/click-worthy version. It doesn't necessarily have to worry about keywords. It doesn't have to worry about accuracy or telling the whole story without any of these other considerations. Step five: Merge 3 & 4, and add in critical keywords.We're going to take three and four and just merge them into something that will work for both, that compromises in the right way, compromises based on your primary audience, your primary goals, and then add in the critical keywords that you're going to need. Examples:I've tried to illustrate this a bit with an example. Nest, which Google bought them years ago and then they became part of the Alphabet Corporation that Google evolved into. So Nest is separately owned by Alphabet, Google's parent company. Nest came out with this new alarm system. In fact, the day we're filming this Whiteboard Friday, they came out with a new alarm system. So they're no longer just a provider of thermostats inside of houses. They now have something else. Step one: So if I'm a tech news site and I'm writing about this, I know that I'm trying to target gadget and news readers. My primary channel is going to be social first, but secondarily search engines. The goal that I'm trying to reach, that's engagement followed by visits and then hopefully some newsletter sign-ups to my tech site. Step two: My title and headline in this case probably need to match very closely. So the social callouts, the social cards and the Open Graph, that can be unique from the meta description if need be or from the search snippet if need be. Step three: I'm going to do step three, author the straightforward headline. That for me is going to be "Nest Has a New Alarm System, Video Doorbell, and Outdoor Camera." A little boring, probably not going to tremendously well on social, but it probably would do decently well in search. Step four: My social click-likely version is going to be something more like "Nest is No Longer Just a Thermostat. Their New Security System Will Blow You Away." That's not the best headline in the universe, but I'm not a great headline writer. However, you get the idea. This is the click-likely social version, the one that you see the headline and you go, "Ooh, they have a new security system. I wonder what's involved in that." You create some mystery. You don't know that it includes a video doorbell, an outdoor camera, and an alarm. You just hear, "They've got a new security system. Well, I better look at it." Step five: Then I can try and compromise and say, "Hey, I know that I need to have video doorbell, camera, alarm, and Nest." Those are my keywords. Those are the important ones. That's what people are going to be searching for around this announcement, so I've got to have them in there. I want to have them close to the front. So "Nest's New Alarm, Video Doorbell and Camera Are About to Be on Every Home's Must-Have List." All right, resolved in there. So this process of writing headlines to serve these multiple different, sometimes competing priorities is totally possible with nearly everything you're going to do in SEO and social and for your website visitors. This resolution process is something hopefully you can leverage to get better results. All right, everyone, we'll see you again next week for another edition of Whiteboard Friday. Take care. Video transcription by Speechpad.com Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! via Blogger Writing Headlines that Serve SEO, Social Media, and Website Visitors All Together - Whiteboard Friday |
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
December 2017
Categories |































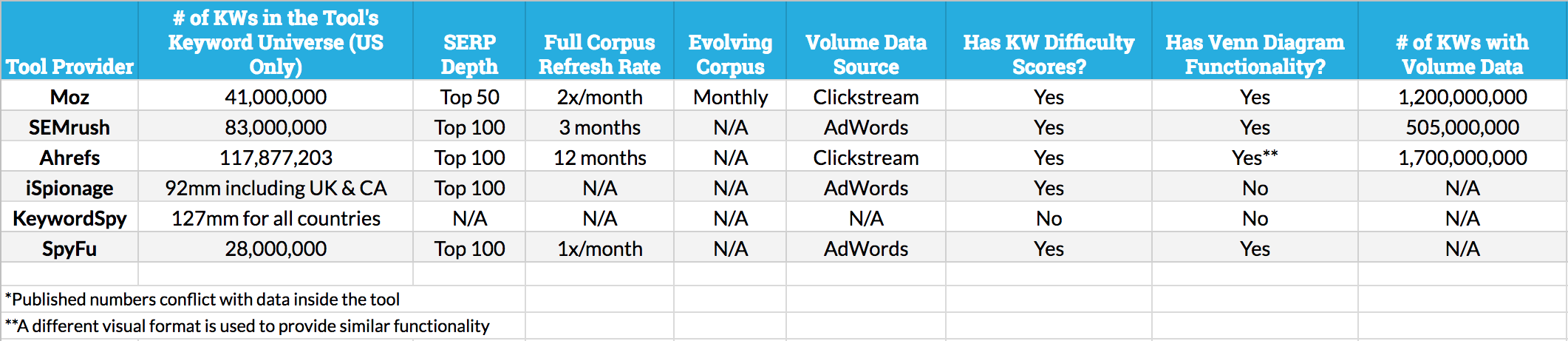



















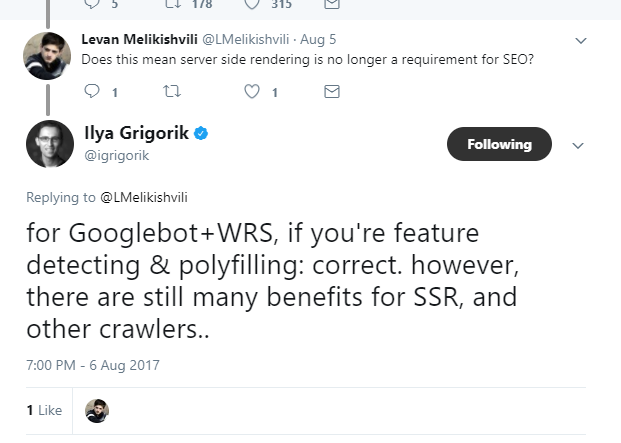

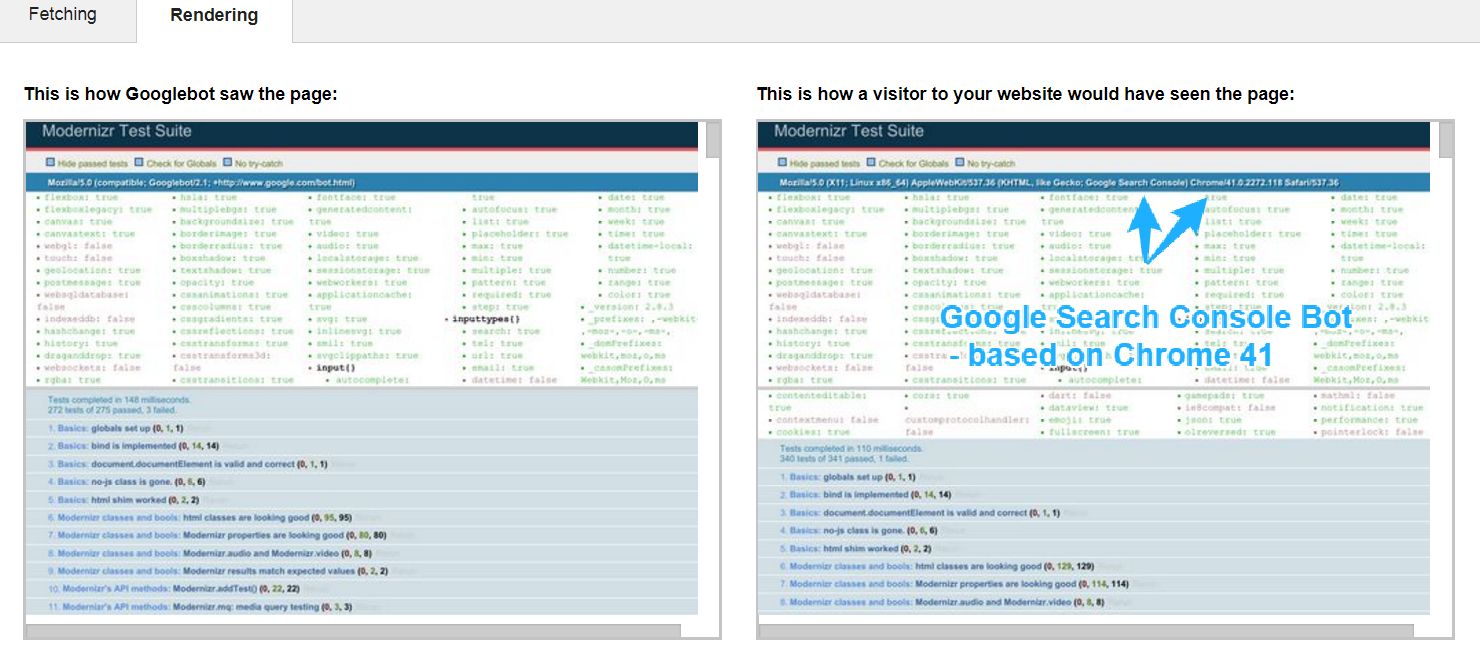


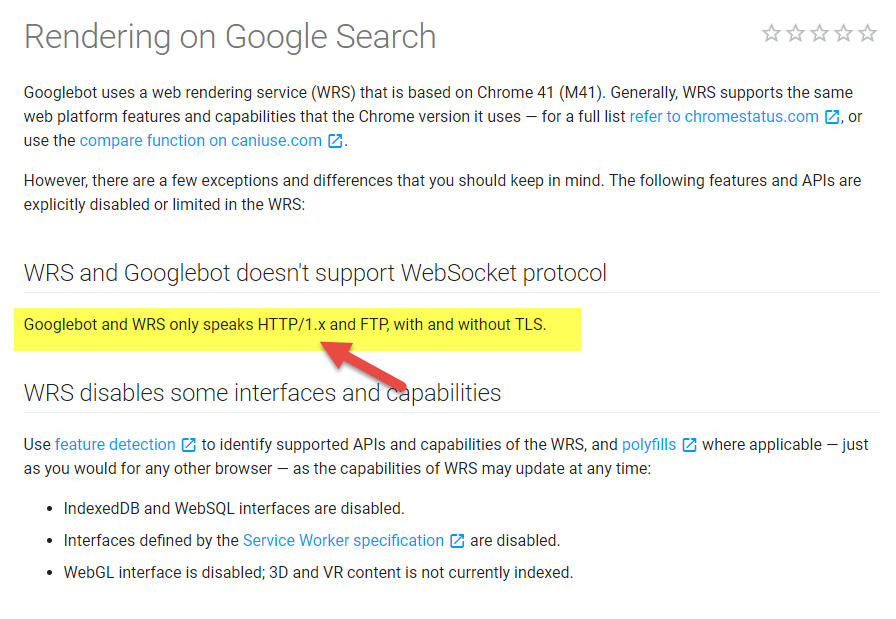














 RSS Feed
RSS Feed
